Motivation
Rehabilitation and automation are two fields where robotics can make a real difference in people’s lives. For stroke patients undergoing upper-body rehabilitation, traditional exercises can feel repetitive and dull, making it hard to stay motivated. By adding robotics into the mix, we can turn these exercises into dynamic and engaging activities that not only boost engagement but also improve muscle activation and recovery. Similarly, in warehouses, many tasks still rely heavily on manual labor. Human-controlled robotic systems offer an exciting way to combine human intuition with robotic precision, creating safer and more efficient workflows—even in challenging environments where signal loss or interference can occur.
This project was inspired by the need to bridge the gap between human intent and robotic action. By using Myo armbands to capture human arm movements and muscle activity through IMU (Inertial Measurement Unit) and EMG (Electromyography) signals, I trained a Multimodal Variational Autoencoder (mVAE) to predict and control a Franka Emika robotic arm. What makes the mVAE special is its ability to handle missing or incomplete data, ensuring the system remains reliable even in less-than-ideal conditions. This versatility makes it a promising solution for both rehabilitation and automation, where adaptability and precision are key.
Mission
The objective of this project is to develop and deploy a robust machine learning framework that translates human arm movements into precise robotic control. Specifically, this includes:
Data Collection and Synchronization Capturing synchronized IMU and EMG signals from the Myo armbands, cube force sensor data, along with the robotic arm’s joint data, ensuring high-quality, multimodal input for training the model.
Data process The data is processed through various filters and downsampling to ensure IMU, EMG, and robot joint data are corresponding with each other when feeding into the model.
Model Training and Adaptation Designing and training a Multimodal Variational Autoencoder (mVAE) to predict and reconstruct robotic joint positions and velocities based on human input. The model’s robustness is enhanced through data augmentation techniques such as time-step concatenation and input masking, allowing it to perform reliably even with partial or noisy data.
Real-Time Deployment Implementing the trained mVAE model to control a Franka Emika robotic arm in both simulated and real-world environments, achieving responsive and accurate robotic movements based on human intent.
By achieving these objectives, the project demonstrates the feasibility of human-driven robotic control and its potential impact in diverse fields.
Data Collection
The data collection process is divided into two parts: Human Arm Data Collection and Robot Data Collection. Both the human and robot perform the same series of tasks to collect their respective data, specifically: picking up and placing a cube.
Task Setup and Board Design

At the start of each trial, the cube is placed at the square-shaped starting position, and both the human and robot begin from their respective home positions. The task is to grab the cube and place it at a target position.
Myo Armband for Human Data Collection
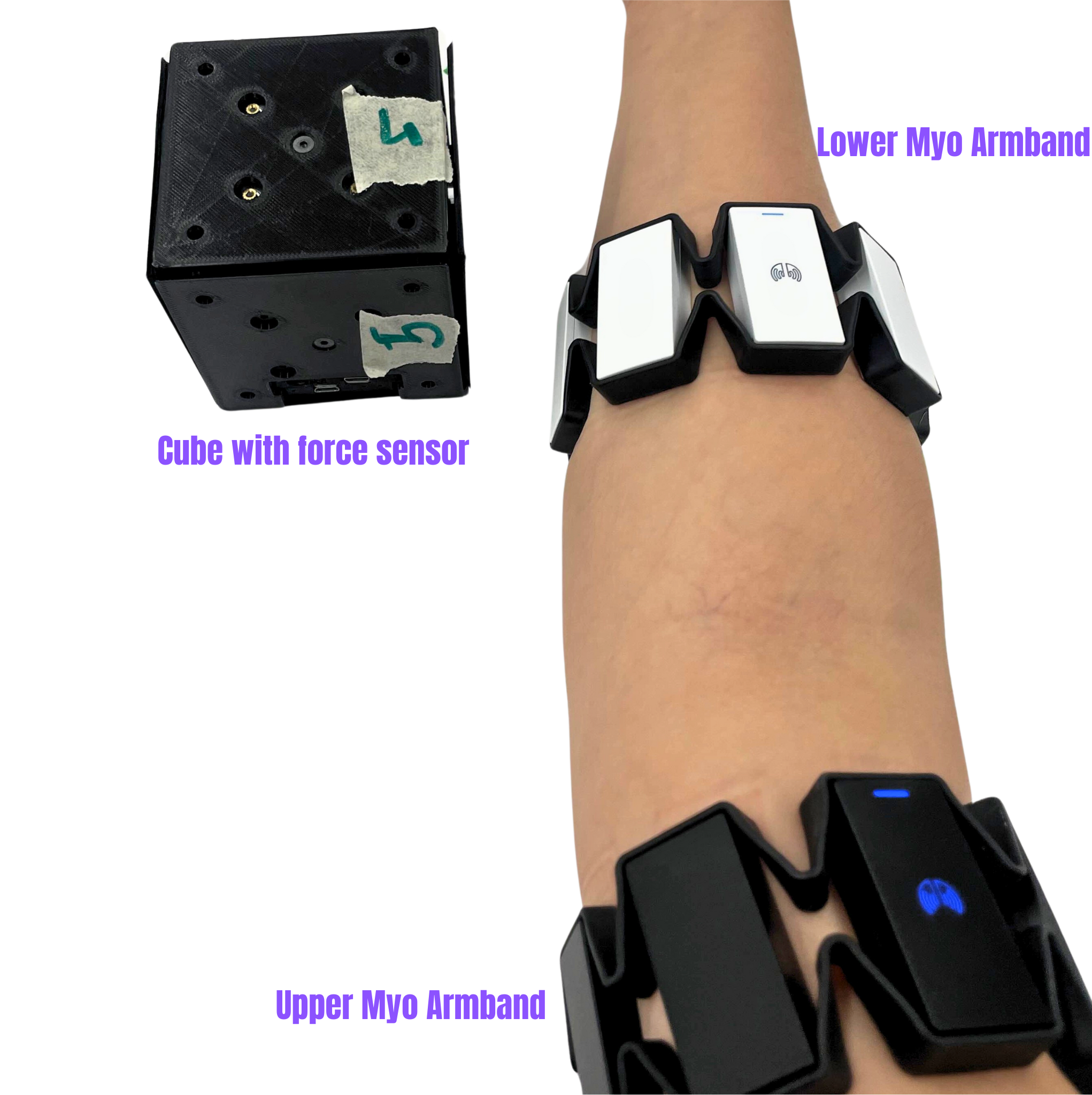
Each trial involves collecting data across the entire task cycle: starting from the initial position, grabbing the cube, moving to the target position, and finally placing the cube at the designated location. To monitor the gripping force, each side of the cube is equipped with a force sensor, which records force data during the task. To ensure robustness and reliability in the machine learning model, the entire task is repeated four times in each trial.
Cube Force Data Collection
A cube equipped with force sensors on each side is used during both the human and robot trials to measure the force applied to the cube. This data will be used to map the force applied by the human’s fingers onto the robot’s gripper strength, which is an important aspect for accurate teleoperation control.
Robot Data Collection
For the robot trials, a Franka Emika robot performs the same task as the human subject. Starting from the same home position, the robot grabs the cube, moves to the target position, and places the cube there. Data collection is managed using ROS2 and rosbag to record the robot’s joint trajectories. The robot’s joint positions and velocities are captured at each timestamp during the trial.
Data Processing
The EMG data is sampled at 200 Hz, while the IMU data is sampled at 50 Hz, resulting in different data lengths within the same trial. To create a consistent dataset, it is necessary to align the EMG and IMU data with the robot joint velocity, position data, and the cube force sensor data.
Human Data Processing
Segmentation:
The EMG data is first segmented based on valid movements during the task, which includes the following phases:
- From the start position to grabbing the cube
- Moving the cube to the target position
- Dropping the cube at the target position
A clustering-based machine learning algorithm is employed to identify the boundaries of the movement phases, dividing the task into distinct segments. This process results in four segments of EMG and IMU data for each trial: one set from the upper Myo armband and another from the lower Myo armband. These segments are then combined to create a comprehensive dataset that captures both muscle activity and movement dynamics, as shown below.

Data Smoothing and Rectification:
Due to the noisy nature of the EMG data, a smoothing and rectification process is applied to improve its quality for machine learning. This helps ensure that the data is cleaner and more suitable for model training.Downsampling:
Next, the EMG data is downsampled to match the time synchronization with the IMU data. Linear interpolation is used to ensure that both the EMG and IMU data segments are aligned in time.Alignment:
After downsampling, the shortest data segment length among all EMG and IMU segments is identified. All other segments are downsampled to this length to ensure uniformity. At this point, each segment (EMG and IMU) will have the same length for each trial.Data Combination:
The four segmented datasets (for both the upper and lower armbands) are then combined into four distinct datasets per trial:- Upper Myo EMG combined data
- Upper Myo IMU combined data
- Lower Myo EMG combined data
- Lower Myo IMU combined data
Each dataset now has consistent data length, representing the human’s performance of the task across all four repetitions in a trial.
A set of one trial’s (4 repetitions) EMG and IMU data is shown below.

Robot Data Processing
Segmentation:
Similar to the human data, the robot data is segmented according to the desired task movements (grabbing, moving, and placing the cube).Downsampling and Alignment:
The robot data is then downsampled to align with the human EMG and IMU data. A low-pass filter is applied to smooth the robot’s joint positions and velocities, ensuring that the data is consistent and suitable for training.Repetition:
Since the robot performs the task once per trial (as the robot follows a fixed trajectory), it does not repeat the task like the human data. To align the robot data with the human data (which has been repeated four times), the robot’s data is duplicated four times to match the four repetitions of the human trial. This ensures that the robot’s trajectory is aligned with the four human data segments in each trial.
A set of one trial’s (4 repetitions) data and a comparison with one repetition of robot data are shown below.
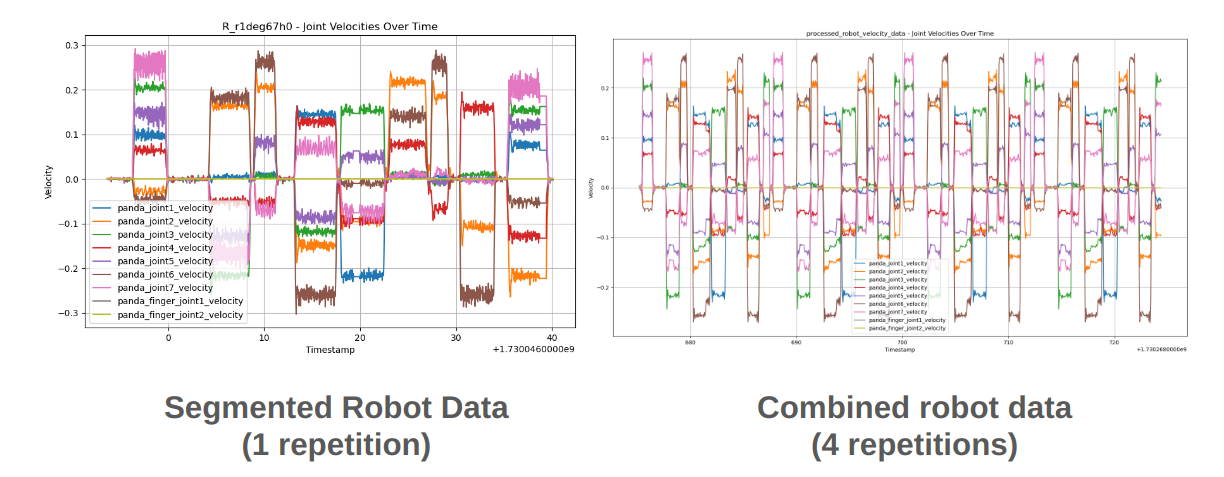
Human Data:
- Segment and cluster EMG data based on task movements.
- Apply smoothing and rectification to the EMG data.
- Downsample and align EMG and IMU data.
- Ensure uniform length across all data segments.
- Combine the data for both upper and lower armbands.
Robot Data:
- Segment robot task movements and apply a low-pass filter.
- Downsample robot data to match human data.
- Repeat robot data to align with the four human task repetitions.
Data Augmentation Process
Normalization:
- The original data is normalized to the range of [-1, 1] using
sklearn.preprocessing.MinMaxScaler. This ensures consistent scaling across all features.
- The original data is normalized to the range of [-1, 1] using
Time-Step Concatenation:
- For each data point at the current time step ( t ), the data is horizontally concatenated with the corresponding data from the previous time step ( t-1 ). This captures temporal dependencies in the dataset.
Dataset Splitting:
- The normalized dataset is split into a training set and a testing set using an 80:20 ratio to ensure an appropriate balance between training and evaluation.
Data Masking for Augmentation:
- Two masked datasets are created:
- Case 2 Dataset: All robot data in the training set is masked with the value -2.
- Case 3 Dataset: All original data at time step ( t ) in the training set is masked with the value -2.
- Two masked datasets are created:
Final Augmented Training Set:
- The original training data is vertically concatenated with the Case 2 and Case 3 datasets, resulting in the final augmented training set. This augmentation ensures the model is robust to incomplete or missing data during training.
Multimodal Variational Autoencoder (mVAE) training and results
Variational Autoencoder (VAE)
Variational Autoencoder (VAE)
A Variational Autoencoder (VAE) is a type of latent variable generative model, consisting of two primary components:
- An Encoder: Transforms the input data ( x ) into a lower-dimensional latent representation ( z ), as follows: $$ z = \text{encoder}(x) $$
- A Decoder: Reconstructs the input data from the latent representation ( z ), such that: $$ x = \text{decoder}(z) $$
The information bottleneck created by compressing the input into a lower-dimensional latent space results in some information loss. This loss is captured by the evidence lower bound (ELBO):
$$ \text{ELBO} = \mathbb{E}_{q(z|x)}[\log p(x|z)] - \lambda \cdot KL[q(z|x) || p(z)] $$
where:
- KL[q, p] represents the Kullback–Leibler (KL) divergence between the approximate posterior q(z|x) and the prior p(z).
- λ and β are parameters used to balance reconstruction accuracy and latent space regularization.
The ELBO is optimized during training using stochastic gradient descent, with the reparameterization trick applied to estimate gradients efficiently. For this study, the focus was placed on the model’s reconstruction capability, so β was set to zero. By concentrating solely on the reconstruction loss, significant improvements in reconstruction performance were achieved.
This project extends the standard VAE to multimodal data, forming a Multimodal Variational Autoencoder (mVAE). The mVAE architecture includes:
- Six Encoders and Decoders: Each corresponding to a specific sensory modality.
- Each encoder and decoder operates as an independent neural network and does not share weights with other modalities’ networks.
- A Shared Latent Representation: All encoders map their respective inputs (one sensory modality) into a shared latent code ( z ).
The network architecture is depicted below:
| Layer | RL_IMU | RL_EMG | RU_IMU | RU_EMG | Robot_Joint_Pos | Joint_Vel |
|---|---|---|---|---|---|---|
| Input Layer | 20 dims | 16 dims | 20 dims | 16 dims | 18 dims | 18 dims |
| Modality Encoders Layer 1 | 100-ReLU | 80-ReLU | 100-ReLU | 80-ReLU | 90-ReLU | 90-ReLU |
| Modality Encoders Layer 2 | 50-ReLU | 40-ReLU | 50-ReLU | 40-ReLU | 45-ReLU | 45-ReLU |
| Concatenation to 270 Dimensions | 270 Dimensions | |||||
| Shared Encoder | 350-ReLU | |||||
| Latent Space | 100-ReLU×2 | |||||
| Shared Decoder Layer 1 | 350-ReLU | |||||
| Shared Decoder Layer 2 | 270-ReLU | |||||
| Slicing | (50, 40, 50, 40, 45, 45) | |||||
| Modality Decoders | 100-ReLU | 80-ReLU | 100-ReLU | 80-ReLU | 90-ReLU | 90-ReLU |
| Reconstructed Data | 20-ReLU | 16-ReLU | 20-ReLU | 16-ReLU | 18-ReLU | 18-ReLU |
Training parameters:
- learning rate: 0.0005
- batch size: 1440
- optimizer: Adam
- training epochs: 80000
Training testsing
- Performance Testing (Metric: MSE)
- Test 1: Predict (reconstruct) robot data from complete original data.
- Test 2: Predict (reconstruct) robot data from human data only.
- Test 3: Predict (reconstruct) all data at ( t ) from all data at ( t - 1 ) only.
- Test 4: Predict (reconstruct) future robot data (at ( t + 1 )) from human data only.
Additional Tests
- Test 5: Feed the human data only to predict (reconstruct) the complete data.
- Test 6: Feed the data at ( t ) only from the previously reconstructed data, then predict the future robot data (at ( t + 1 )).
Results and Plots
The results for each test and the plots for Test 4 (comparing the original position/velocity at ( t ) with the predicted position/velocity at ( t + 1 )) are shown below:
| Test | Joint_pos_cur (at t) | Joint_vel_cur (at t) |
|---|---|---|
| Test 1 | 0.0047 | 0.0091 |
| Test 2 | 0.0414 | 0.0384 |
| Test 3 | 0.00502 | 0.011 |
| Test 4 | 0.0502 | 0.0481 |
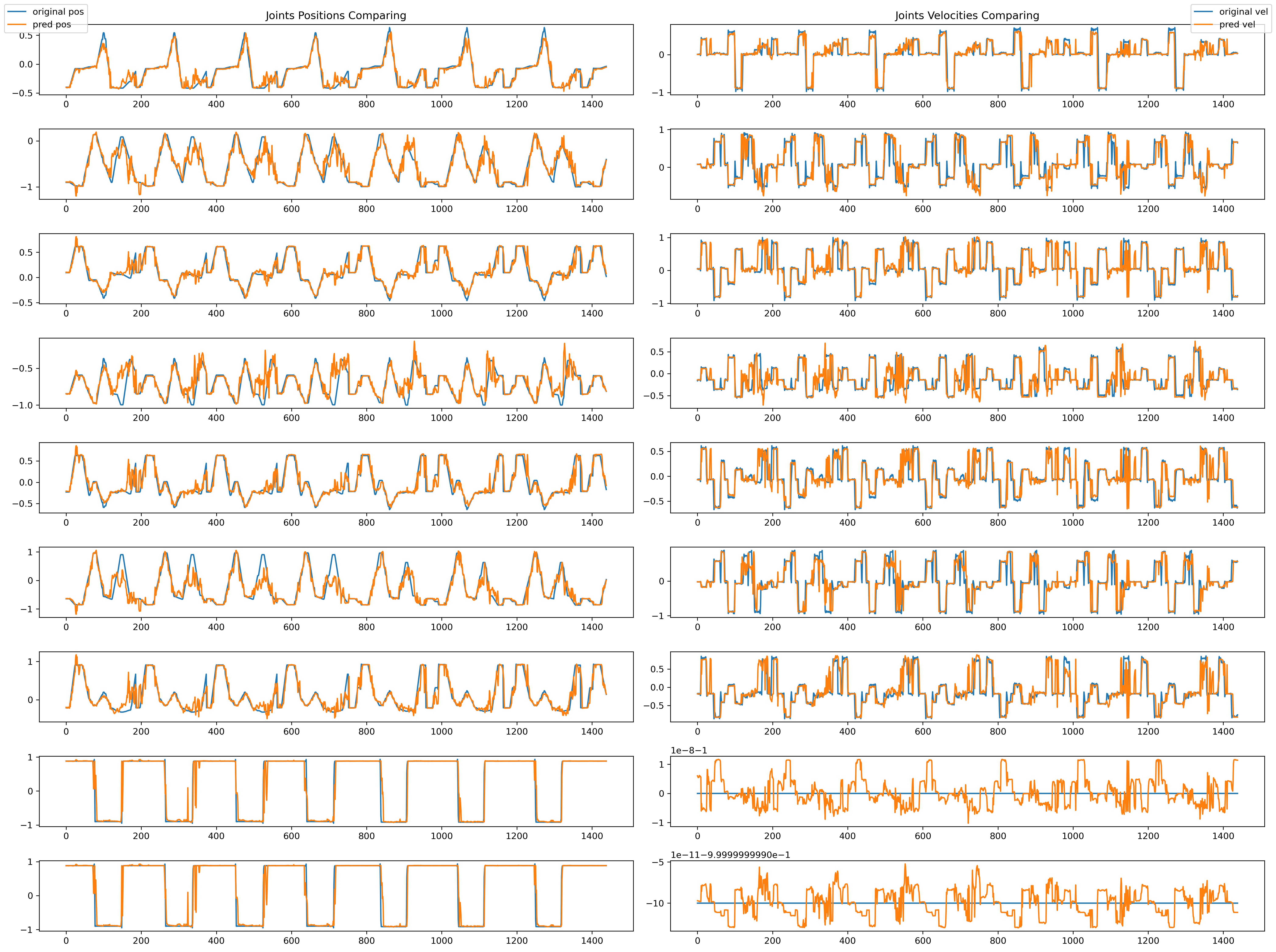
Discussion
The ultimate objective of this project is to predict future robot motion by monitoring current human motion, as depicted in Test 4. However, conducting the previous three tests provides valuable insights into the performance of individual components.
Test 1 and Test 2:
- Test 1 demonstrates that the prediction error for robot data is minimal when using complete data as input.
- Test 2 shows that while the error increases when only human data is used as input, the model still achieves excellent performance for position prediction.
Test 3:
- Predicting data at time ( t ) (both human and robot data) from data at time ( t - 1 ) yields performance comparable to Test 1.
- This consistency suggests that a one-time-step shift at 10 Hz does not significantly alter the state. Future work could explore incorporating larger time shifts to better evaluate prediction performance across more dynamic scenarios.
Test 4:
- This test combines the functions of Test 2 and Test 3, involving two stages of reconstruction:
- Initial Stage: Human data is used to reconstruct the data at time ( t ).
- Secondary Stage: The reconstructed data at time ( t ) is fed as input for predicting data at time ( t - 1 ), ultimately enabling prediction of data at ( t + 1 ).
- From the plots, it is evident that:
- Position Predictions: Closely align with the ground truth positions.
- Velocity Predictions: Match the general trend of ground truth values, although some extreme points in joints 1, 2, and 4 were missed by the model.
- These missed points correspond to boundary values ((-1) or (1)) in the dataset, highlighting a potential area for improvement in the model’s handling of edge cases.
- This test combines the functions of Test 2 and Test 3, involving two stages of reconstruction:
Overall, these tests provide a comprehensive evaluation of the model’s prediction capabilities and outline areas for potential future enhancements.
Related GitHub Repositories
- ROS2_Myo_Franka: A repository for connecting Myo armbands to the Franka Emika robot, including data collection and integrating machine learning pipelines into robot control.
- mVAE_robot_human_training: A repository for training the processed robot and human data.